Data Engineering
![]()
Visual Flow for Building ETL Pipelines
An ETL tool powered by Apache Spark on Kubernetes.
Simplify ETL with a Drag-and-Drop Interface. Visual Flow reuses Argo Workflows, Kubernetes orchestration, and Spark ETL. Scale at the Speed of Data.
WHAT CHALLENGES DO COMPANIES FACE?
Companies use Enterprise Data Warehouses (DWH) and Data Lakes to collect and accumulate a large amount of information. The problem arises when enterprises try to combine unstructured and conflicting data from different sources. Data may be lost, duplicated, and logical conflicts occur. This leads to lower quality of data and analytical reports based thereon.
WHAT IS DATA ENGINEERING?
Data Engineering is programming for the collection, storage, processing, retrieval and visualization of data.
Data Engineering helps build stable ETL and ELT processes for data mining and origination for analytics systems, machine learning algorithms, Data Science.
High-quality data becomes available in the proper form to employees of the company.
WHAT ARE THE BENEFITS FOR THE COMPANIES?
Transparency of data collection processes from external and internal sources, its storage, processing and transfer to corporate systems.
Accurate analytics models, for example, to predict customer attrition, fraud, etc.
Relevant processed data for analytics systems, machine learning algorithms and Data Science
What we do
Extract the relevant information from the data
We develop and implement the processes of data extraction, transformation and loading (ETL and ELT processes), methods of data quality monitoring and data masking (DQM), we design processes for distributed computing.
NEW Improve loading and cleansing data using Visual Flow. This is a new ETL tool for Data Engineers, Data Migration Managers, Low- to No-Code ETL Developers.

Identify the key values and interpret the results
We introduce analytics systems that can process current data: generate reports and make forecasts. If necessary, we set up prescriptive analytics to test hypotheses and obtain probable scenarios of developments.
Integrate data from multiple sources into a single database
We develop Data Warehouses and Data Lakes based on the solutions of classical DBMS, MPP (Multi Parallel Processing) DBMS and Big Data (distributed computing). Solutions are capable of processing large amounts of information and data streams in real time.
Facilitate the access of applications and data from any location worldwide and from any device
We migrate from on-premise to the cloud both within the same and different vendors.
- Reduce CAPEX on in-house hardware
- Allocate cloud resources efficiently among company’s departments
- Work on a project together with customers in the same environment
- Prevent data loss
More about Cloud Solutions
DATA ENGINEERING EXPERTISE IN CLOUD SERVICES
We deploy and customize cloud infrastructure




DATA ENGINEERING IN THE HIERARCHY OF DATA MANAGEMENT
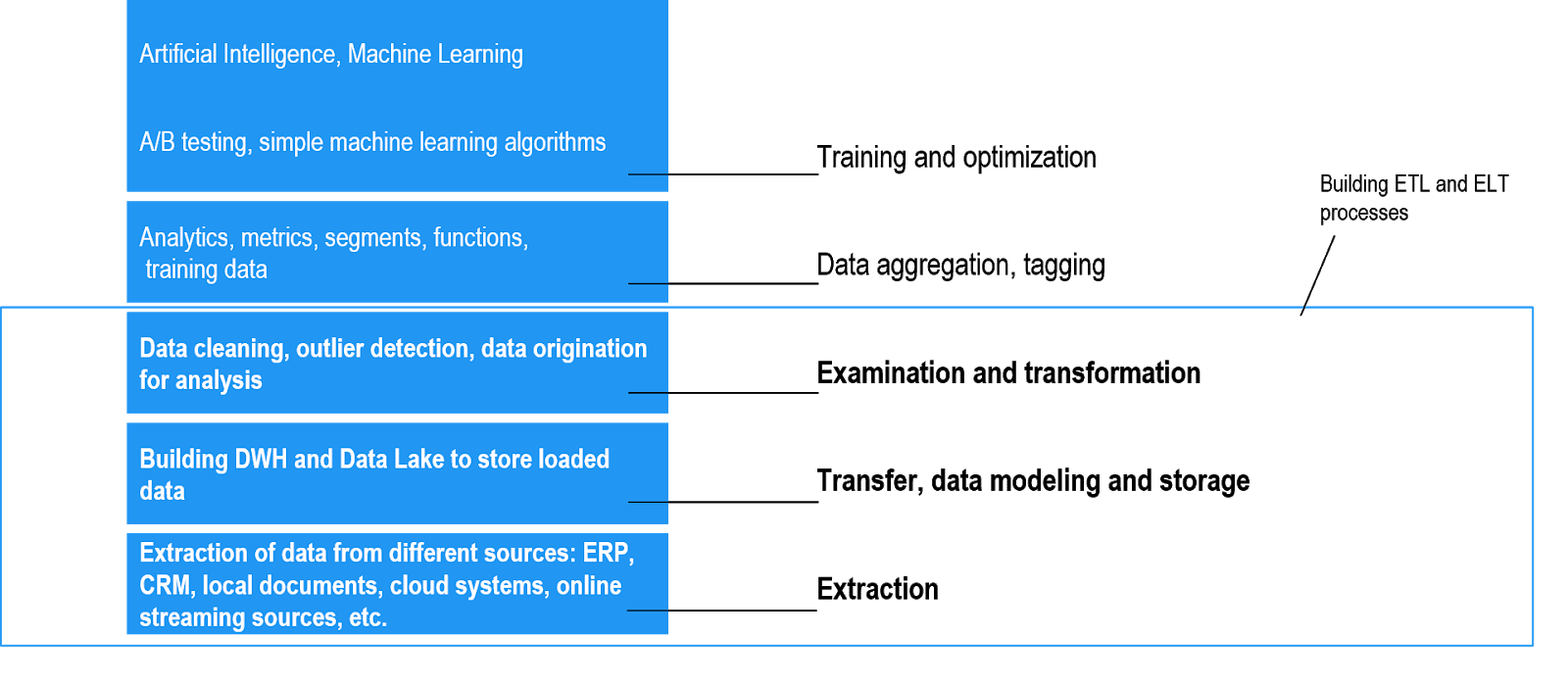
KEY DIFFERENCES OF ETL AND ELT PROCESSES
An ETL process deals with data the structure of which is determined in advance when designing DWH. Data transformation takes place in the processing area, and processed information that meets standards, such as GDPR, HIPAA, etc., enters the target systems.
With ELT processes, any data is loaded into Data Lake or target systems and is processed after loading. This approach provides more flexibility and simplifies storage when new data formats evolve.
ETL Process
Extract
Data is extracted from external and internal sources: ERP, CRM, local documents, the Internet, cloud systems, IoT sensors and other online streaming sources, etc. Then it is transferred further for conversion.
 |
Transform
Data is cleared, filtered, grouped and aggregated. Raw data is converted to a set ready for analysis. The procedure requires an understanding of business challenges and basic knowledge in the field.
|
Load
Processed structured data is loaded into DWH or target systems. The resulting data set is used by end users or as an input stream to another ETL process.
ELT Process
Extract
Data is extracted from external and internal sources: ERP, CRM, local documents, the Internet, cloud systems, IoT sensors and other online streaming sources, etc.
|
Load
Raw data is loaded to Data Lake or target systems. Then the data is converted.
|
Transform
Data is cleared, filtered, grouped and aggregated. An ELT process can only process the portion of the data that is necessary for a specific task.