What Makes a Difference in Effective AI Adoption? Nothing Other Than Data Quality
While artificial intelligence and machine learning solutions have been developing at a dizzying pace, penetrating various spheres of our daily lives and reshaping entire industries, many businesses have already learned that the adoption of these technologies is not all roses. In this article, we’ll discuss the crucial role of data quality in AI implementation and share some data quality practices that will help you set up your innovative projects for success.
Table of Contents
Successful AI Adoption: Data Is the Key
According to Vanson Bourne’s study conducted in 2024 among 550 respondents representing companies from the US, UK, Ireland, France, and Germany, about 90% of the organisations are investing in AI models to unleash the fantastic power of predictive analytics and use the insights for better decision-making. From predictions used to forecast demand and improve supply chain efficiency to RPA implementations leading to an 84% reduction in manual work and 100% business process accuracy, AI is transforming many industries.
 However, the same survey revealed that 42% of the respondents admitted to suffering from ‘AI hallucinations’, with another 40% saying their AI models were not free from biases. Moreover, the underperformance of AI projects caused by poor AI data quality can result in incorrect business decisions, which can, in turn, lead to quite measurable financial losses — up to 6% of annual revenue on average.
However, the same survey revealed that 42% of the respondents admitted to suffering from ‘AI hallucinations’, with another 40% saying their AI models were not free from biases. Moreover, the underperformance of AI projects caused by poor AI data quality can result in incorrect business decisions, which can, in turn, lead to quite measurable financial losses — up to 6% of annual revenue on average.
Everything is simple here — unlike traditional app development, which relies on coding, AI projects are all about data. AI and ML systems use it to learn and make recommendations: they reveal patterns in the information provided for their training, teach themselves those characteristics, and then compare them with new observations to generate a solution. If there is not enough data or if the data quality for AI training is dubious, the project will be doomed to failure. In fact, research shows that up to 80% of AI projects fail to deliver the expected benefits and that poor data quality in AI systems is one of the top three reasons for the fiasco.
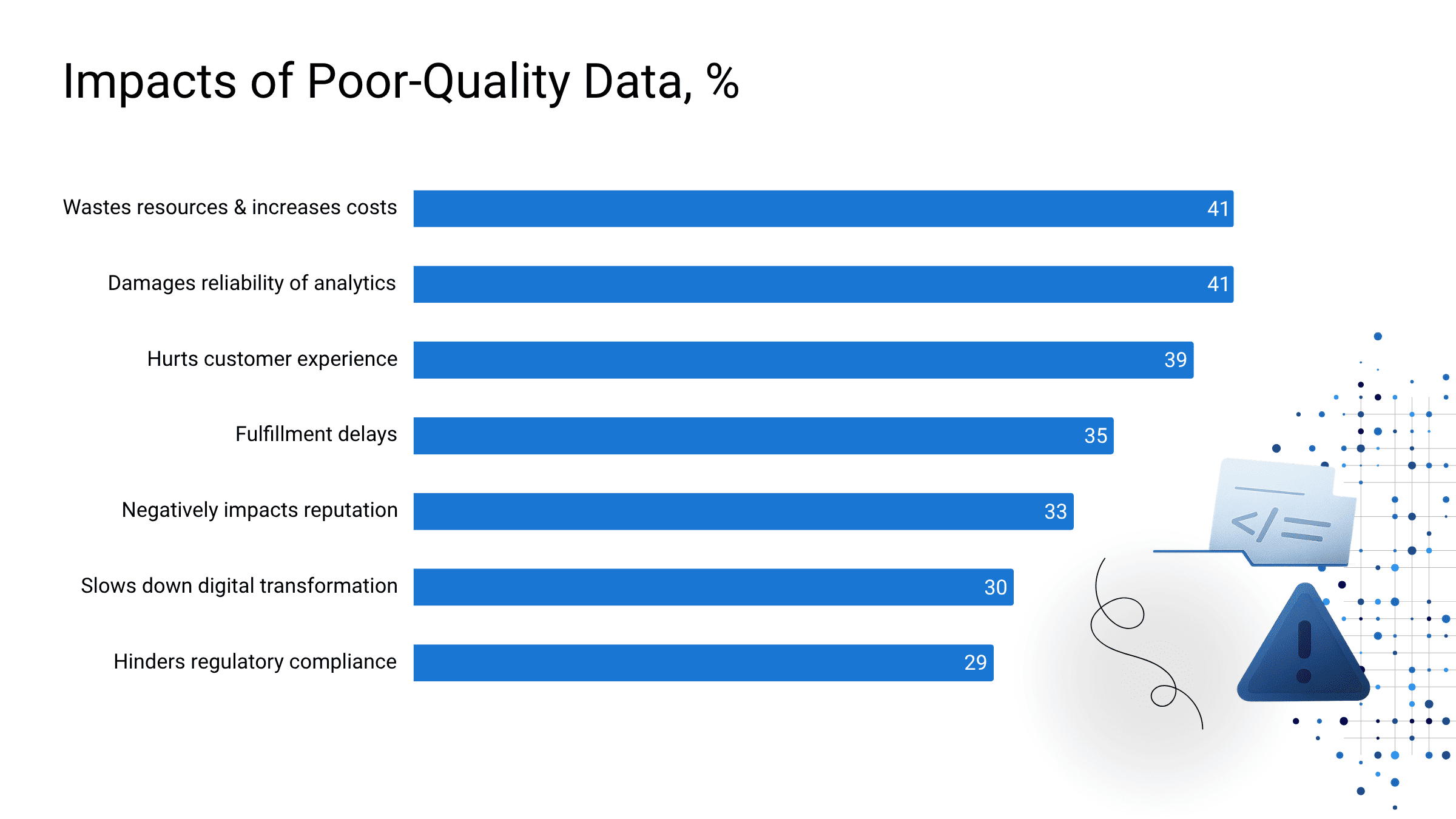
SOURCE: Experian 2021 Global Data Management Research Report
The good old GIGO concept (garbage in, garbage out) is totally applicable to AI deployment since, regardless of how smart the models are, they are still just algorithms that will consume and process everything you feed them. If the information is incomplete, inaccurate, irrelevant, or flawed in some other way, the results cannot be trustworthy. For example, research by MIT Media Lab proves that poor data quality in AI-powered facial recognition systems can increase the error rates by up to 34.7% in identifying darker-skinned females against 0.8% for lighter-skinned men — all because of a lack of diversity in the training datasets.
Unfortunately, many businesses focus on dealing with the volume of information generated by their systems rather than on ensuring ML data quality, trying to use datasets that are not AI-ready. Although data quantity and diversity also play a vital role in AI success, providing a great opportunity for the algorithms to capture more nuances for enhanced outcomes, big datasets thrown into AI systems without adjusting data quality for machine learning can only amplify the “garbage out” problem. So, businesses wishing to successfully overcome the most common AI data challenges and ensure AI algorithm accuracy need to shift their focus and start with data profiling.
Digging into Data Quality for AI with Data Profiling
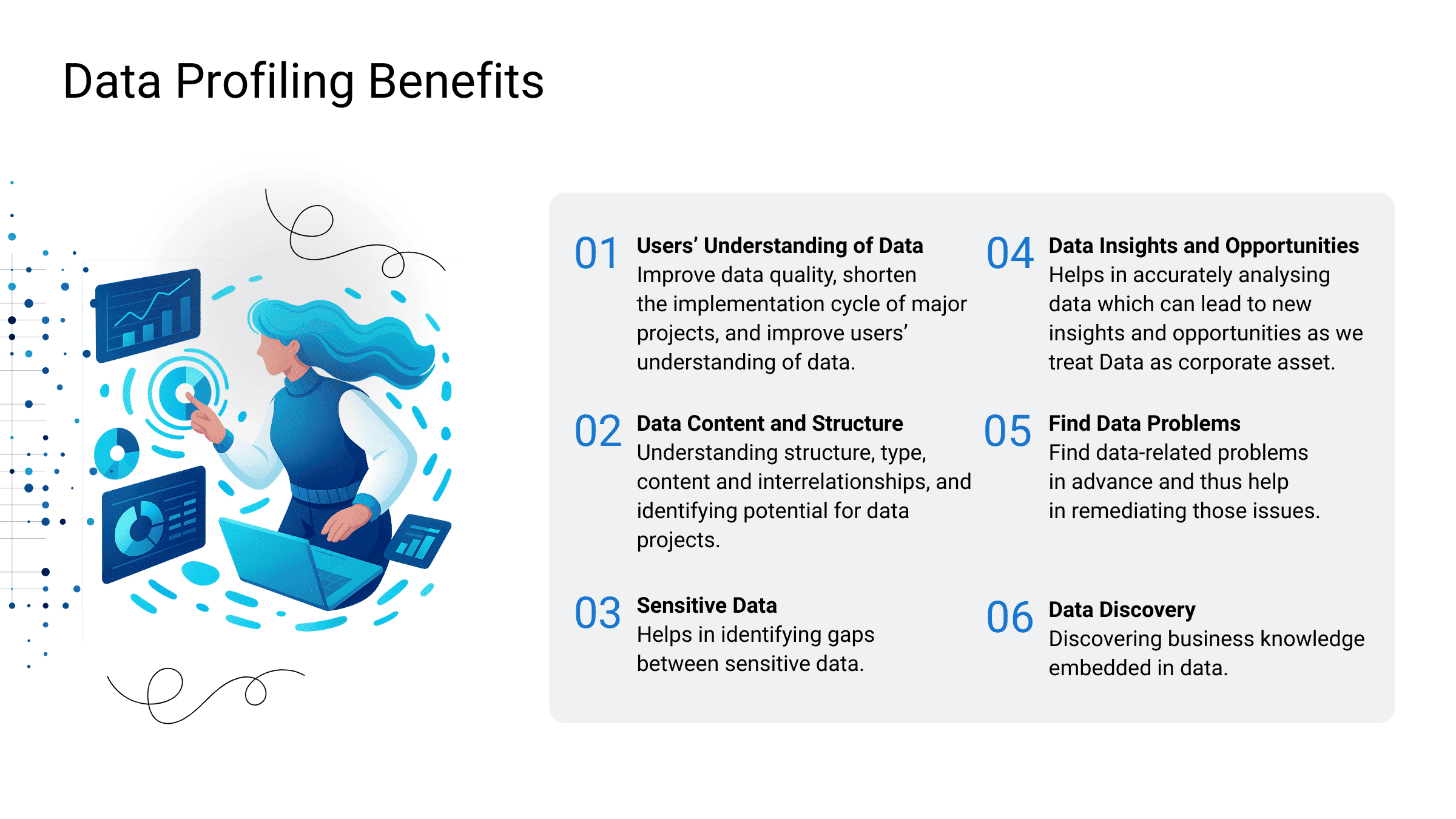
Data profiling is one of the key data quality techniques. It is aimed at reviewing data available in a company’s information sources, summarising it and evaluating its quality. It allows companies to better understand the structure of their data, standardise and organise it in a convenient way, improve its credibility and searchability, and, finally, enhance data quality for AI applications. To this end, analysts usually work on three levels:
- Structure. On this level, they typically use pattern matching, where datasets are checked against known patterns to ensure data consistency and uniform formatting. For example, email addresses can be scanned to verify they all have the at sign (@), or phone numbers can be examined to make sure they have the correct number of digits. Structure discovery also produces useful statistics on the datasets, such as min, max, and mean values, which can be further used for data validation, namely, when you spot a value that doesn’t fit into the stats.
- Content. Here, analysts focus on individual records and their values to reveal possible errors and anomalies. For example, you may find out that some records contain different values for the same area, such as CA, Cali, Cal, and Calif for California state. Without content discovery, you may not even know that this problem exists, and, as a result, your querying may provide incomplete outputs that affect business decisions.
- Relationships. This level works towards maintaining data integrity by detecting connections across different datasets. Relationship discovery can cover associations between various tables, such as a customer ID field common for databases used in multiple departments, or between cells within one table, such as a cell value calculated based on other cell values. In any case, identifying and recording these interdependencies are crucial for the proper work of complex systems, integrations of new information sources, and data import.
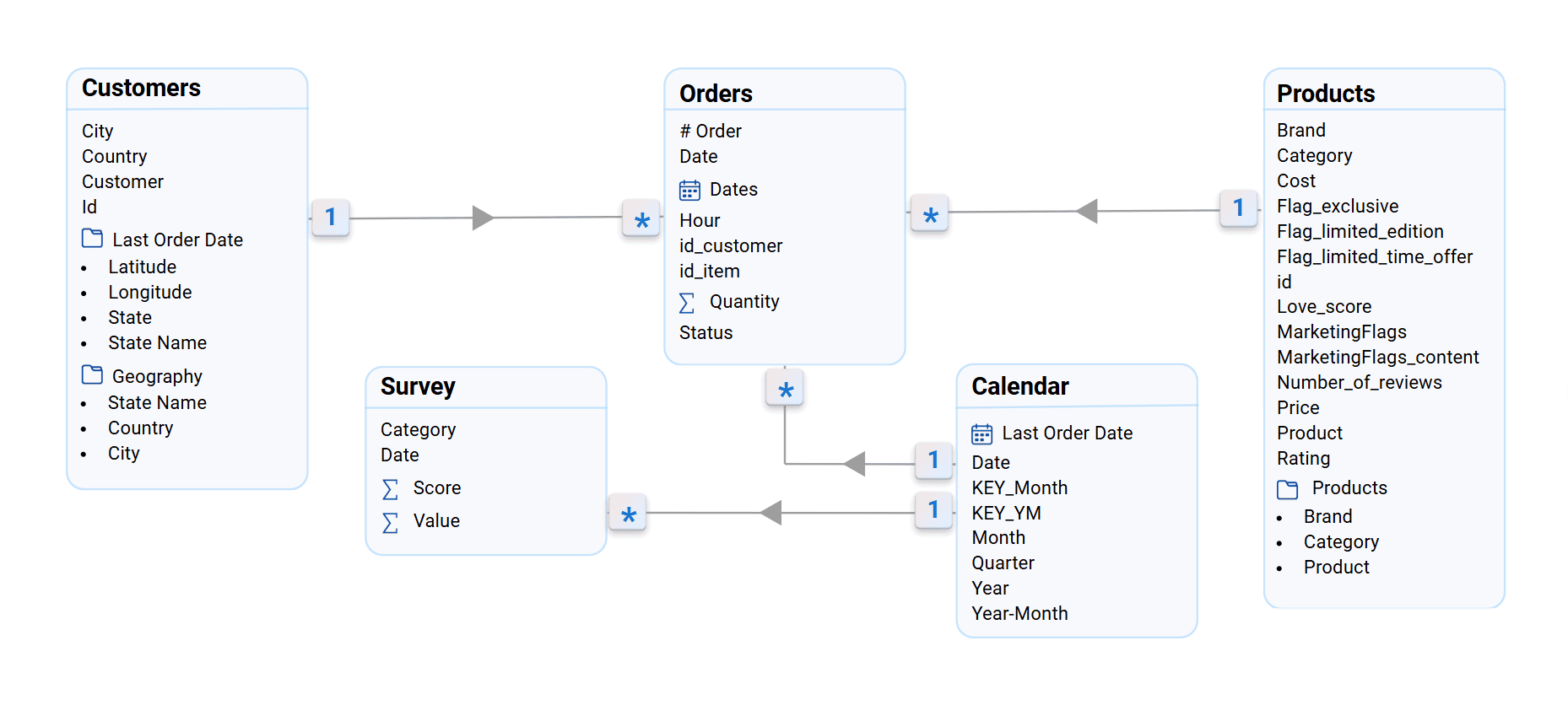
Here is a data model reflecting relationships between different tables created by engineers at the IBA Group when performing data profiling within analytical app development for e-commerce.
All in all, to ensure high data quality in AI models, data profiling requires:
- collecting descriptive statistics, such as standard deviation, frequency, mode, median, and minimum/maximum values;
- identifying data types (numerical, categorical, date, and so on) and length;
- revealing recurring patterns and assigning tags such as keywords or descriptions;
- discovering metadata and checking it for accuracy and completeness;
- finding issues, including inconsistencies, duplicates, and errors, and fixing them for data quality enhancement;
- examining dependencies to locate primary and foreign key candidates;
- evaluating that the data aligns with the company’s business goals.
While performing comprehensive analysis and data cleansing, analysts assess data quality for AI systems using a set of metrics that can be measured with the help of dedicated tools and tracked to evaluate the effectiveness of their improvement efforts.
Metrics for Tracking AI Data Quality
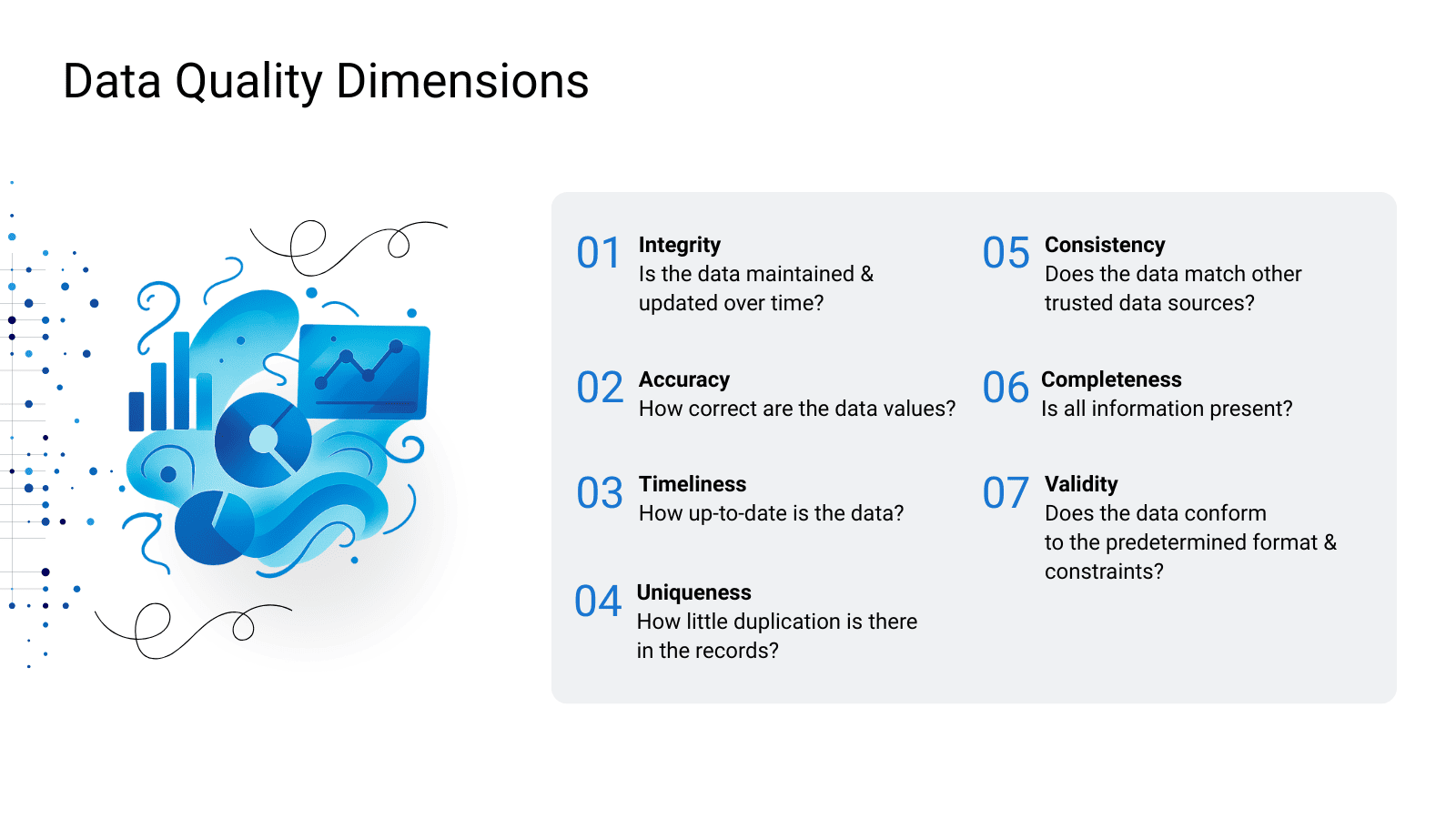
Although professionals still cannot come to an agreement about how to define data quality, they have a consensus that the following characteristics play a crucial role in data quality management:
- Completeness. Missing pieces of information compromise data quality in AI projects, making the algorithms overlook important patterns and connections, which results in incorrect predictions and decisions. Within AI data preparation, missing information is identified and measured either at the record level, represented as a percentage of incomplete records, or at the attribute level, displayed as a percentage of objects with a null or dummy-assigned attribute.
- Accuracy. Inaccurate records have errors and anomalies like values going beyond acceptable limits. They, therefore, fail to correctly reflect real-life situations, leading AI to make improper conclusions. In this respect, analysts can perform data quality measurements by calculating the error ratio and comparing datasets against standard deviation.
- Consistency. Information that doesn’t align across different systems is yet another of the common AI data issues. If there are contradictions in the provided datasets, such as mismatching addresses in a customer’s records stored in a CRM and a customer support app, the algorithms can easily end up in confusion. Standard deviation, percentage of attribute mismatches, and percentage of incomplete transactions can be calculated to evaluate machine learning data quality from the consistency perspective.
- Validity. Invalid data doesn’t comply with predefined rules, hindering processing and impairing the performance of AI models. For example, a date of birth entered in the wrong format may become completely unusable for your purposes or negatively impact the accuracy of your analytics. Metrics like the percentage of valid records will help to assess the validity parameter.
- Uniqueness. Duplicate records often appear as a result of merging information from several sources, undermining data quality in AI systems and skewing outputs. Analysts can identify and remove these redundancies by measuring the duplicated business key ratio and duplicated transaction record percentage.
- Referential integrity. Ensuring that references in and between tables remain legitimate as data is transformed, referential integrity is an important concept in both relational databases and synthetic data used to train ML models. The percentage of rows having no valid parent reference and the percentage of out-of-hierarchy records help analysts eliminate invalid relationships between data objects.
- Inter-system integrity. This metric shows whether data migrated from multiple systems remains intact and whether inter-system data is complementary or overlapping. Analysts can monitor the percentage of data that is the same across multiple systems and the percentage of master data mismatches.
- Timeliness. Outdated information is sure to do no good for data quality for AI systems, leading to irrelevant outputs and bad business decisions. By calculating the amount of time required to gather relevant data and the amount of time needed for the data infrastructure to propagate values, analysts can check if the information is up-to-date for its intended use.
Depending on business and technological needs, data quality measurement can include other, more specific metrics, such as auditability and gap/overlap analysis. To uncover most of these AI data issues, analysts have to understand basic business and source system logic. The problems identified during AI data quality assessment are tagged based on whether they can be resolved through data cleansing using ETL processing.
5 Steps in Assessing Data Quality for AI Models
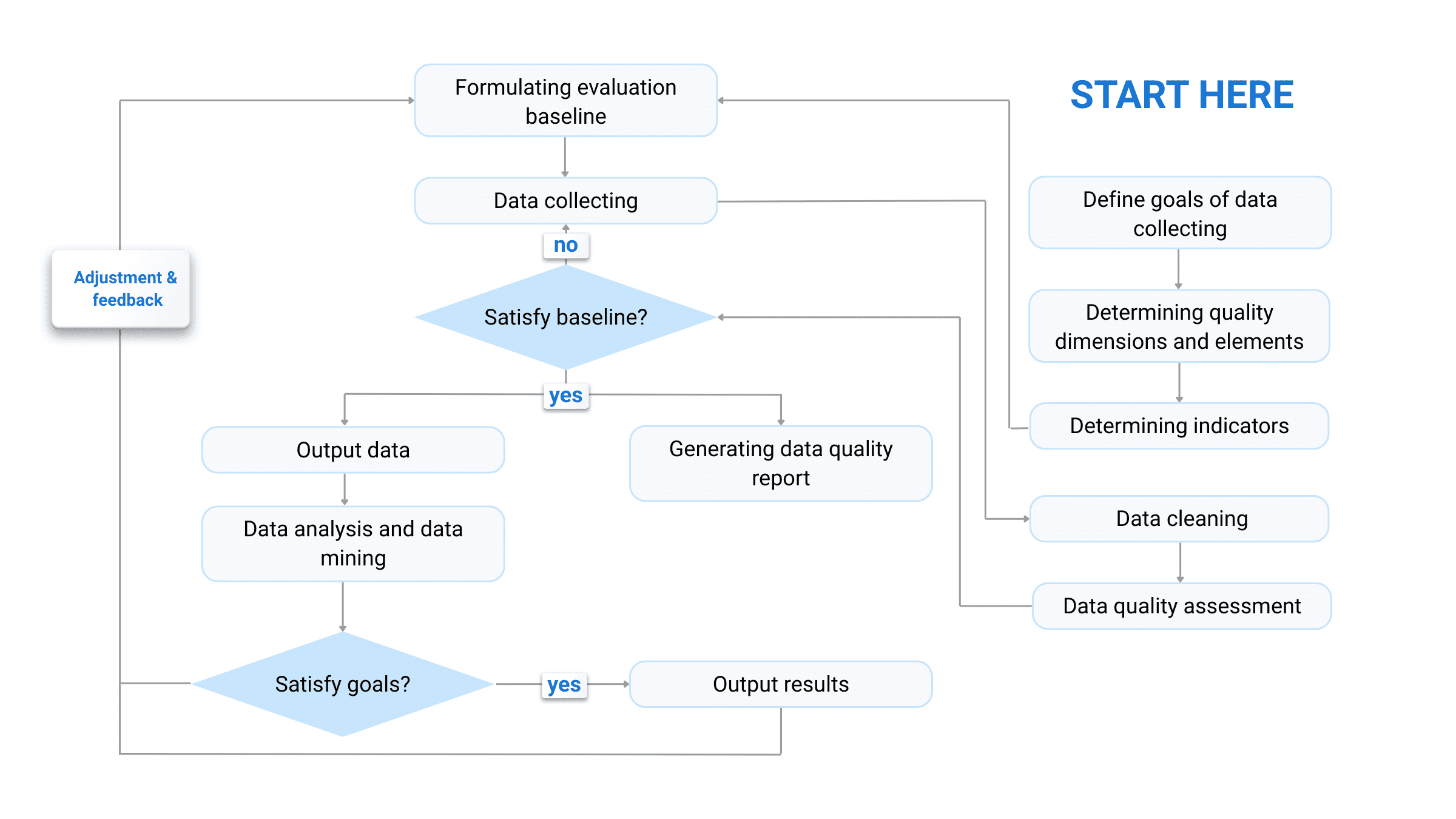
Data profiling goes hand in hand with data assessment, although the first process is more focused on understanding data structure, content, and connections, while the second actually evaluates data condition in terms of its suitability for a specific use. As such, data profiling is the first step in AI data preparation, followed by designing an action plan to enhance and maintain data quality in AI projects. Usually, the assessment process includes the following stages:
1 / Collecting business requirements, business intelligence, and system logic insights; 2 / Detailed process estimation, including the scope of data, metrics, raw data formats, and results representation; 3 / Setting up infrastructure; 4 / Assessment execution:
5 / Approval of the results and defining further steps. |
Ultimately, the assessment creates a clear picture of the condition of the data and provides vital metrics for both immediate ML data quality improvements and ongoing data quality monitoring. Although all these processes can be performed manually with some effort and knowledge applied, it is much more effective and less time-consuming to enhance data quality for AI with the help of dedicated tools, which we are going to explore in the second part of this article.
YOU MAY ALSO BE INTERESTED IN
- Databricks vs Snowflake: Is There Really a Winner?
- On the Way to Lakehouse
- Cloud vs On-premises: What is Better for Business?
- Why Migrating to the Cloud Brings Value
- Data Migration to Cloud: What You Will Get in the End
- Why Migrating to the Cloud Brings Value
- ETL/ELT: What They Are, Why They Matter, and When to Use Standalone ETL/ELT Tools
- Data Literacy: The ABCs of Business Intelligence
- BI Tools Comparison: How to Decide Which Business Intelligence Tool is Right for You
- Unsuccessful examples of BI development. Part I
- Examples of Unsuccessful BI Development. Part II
- BI Implementation Plan
- IBA Group Tableau Special Courses
- Integrating Power BI into E-Commerce: How to Succeed in Rapidly Developing Markets
- Analytics vs. Reporting — Is There a Difference?
- Better Business Intelligence: Bringing Data-Driven Insights to Everyone with IBM Cognos Analytics 11
- Building a Data-Driven Organization: From Data to Decision