ETL/ELT: What They Are, Why They Matter, and When to Use Standalone ETL/ELT Tools
Introduction
In the previous article, we talked about all BI related things. We gave an overview of BI implementation without diving too deeply into its details and nuances. As we’ve covered, the heart of all BI is data, and data needs to be prepared before getting sent to a BI system. The process of data preparation revolves around two key concepts: Extract-Transform-Load (ETL) and Extract-Load-Transform (ELT). This article will examine what these terms mean, how they’re different, and how to use them to your advantage.

Why is ETL/ELT important?
Data can be processed with the help of a BI system and/or specialized third-party systems. But, especially for more complex projects, not all BI tools have embedded ETL/ELT functionalities that offer powerful enough data processing capabilities. When a BI tool’s native abilities are not enough, you need to use independent ETL/ELT tools.
For larger projects, the Transform stage should be separated into its own functional block. This allows you to use the processed data in any system — not just BI systems. It also makes it easier to understand the architecture and divide the project into stages of working with the data and data visualization.
In each specific case, one needs to decide whether to separate ETL/ELT into a distinct functional block based on analysis of the existing BI product, its advantages and disadvantages, the project infrastructure, and available server capacities.
You will face different challenges while working with data, but still there is no perfect answer to your questions. Thus, you need to combine various architectural approaches to solve problems with maximum efficiency.
Defining ETL and ELT
As you might have guessed, Extract-Transform-Load and Extract-Load-Transform differ according to the order of the last two stages, Transform and Load. Anyway you will use basic principles of ETL/ELT. Difference will be chiefly in your volume of data, possibility to handle it with a BI tool itself or additional ETL/ELT software.
All BI systems work with data. As we have mentioned elsewhere, it is near-impossible to take rough data and immediately build analytics. Before beginning the data analysis process, you will need to:
- Identify and select the data you need (extract, possibly from several different sources)
- Convert it to a common order and format (transform)
- Store the data in a common location (load)
Many BI tools have their own data transformation functions. However, they all work based on clear Structured Query Language (SQL) principles. For example, in the basic version of any BI tool, you connect to a data source (extract) and move data to the target storage (load), then design the models you need and do all sorts of transformations — converting data to a certain format, performing various calculations, and much more (transform).
Alternatively, after connecting to a data source (extract), you make all necessary calculations and transformations first (transform), and only then enter a ready-made data cast into the interface (load) for further visualization and analysis.
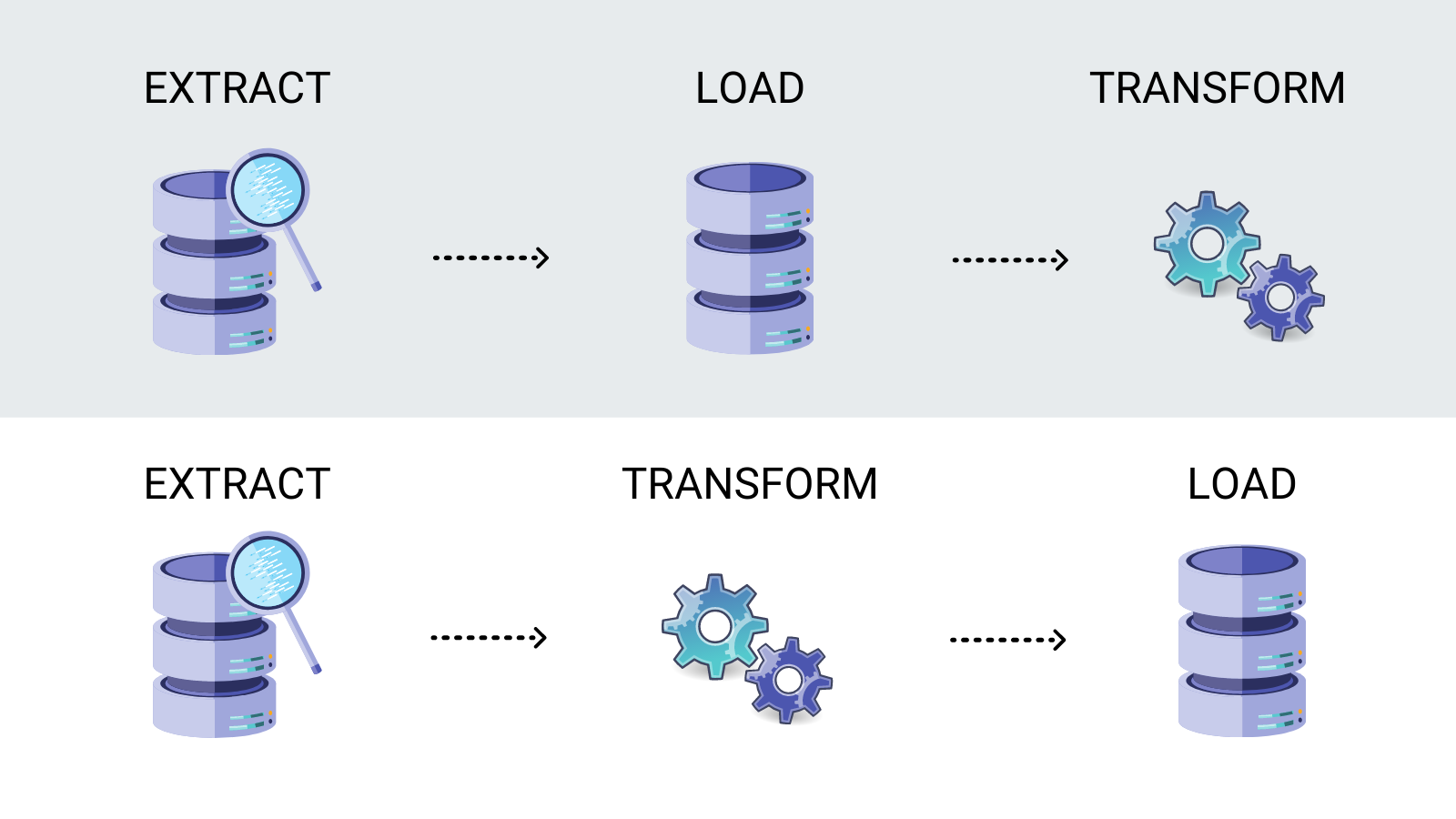
TAKEAWAY: ETL/ELT – it is just a term that describes a sequence of data manipulation
So, how do you decide between ETL and ELT?
It all depends on your project. During the technical analysis stage of your project, while assessing its strategic development and budget limitations, you will have an opportunity to choose the most effective infrastructure. BI tools with powerful embedded ETL capabilities can usually handle small and medium projects.
If your project deals with a high and growing volume of data, it becomes necessary to implement a standalone ETL/ELT product to complement the BI tool. Depending on your needs you can choose between ETL/ELT tools with different functionality and price.
We want to emphasize the importance of creating a long-term strategy for the product. If it is a well-thought-out strategy and contains the prerequisites for the implementation of full-fledged ETL/ELT, it will naturally avoid the pitfalls of introducing additional functionality.
TAKEAWAYS:
- BI tools with powerful embedded ETL functionality can handle ETL/ELT processes for small- and medium-sized projects; standalone ETL solutions are best for large, complex projects.
- When implementing a standalone ETL/ELT system, adopt a rigorous analysis and development approach.
The role of Data Engineers
Now, what kind of specialist will you need to deal with ETL/ELT?
You can come across specialists like ETL/ELT developers and Data Engineers. In fact, they perform the same function, the only difference being the tools and programming languages they use along the way. All of them are well-versed in best practices around building data warehouses, data models, methods, and work techniques. To avoid confusion we prefer to solely use the concept of Data Engineers dividing them into “soft” and “hard” data engineers.
What type of Data Engineer should you choose?
Choosing the right specialist depends on the project’s needs, the volume of data, and the agreements you set with a particular vendor. These criteria will determine whether you choose a soft or a hard data engineer.
For projects with well-structured data where you exactly know what you need and how to get it, you should look for a soft data engineer. Such engineers work with classic ETL/ELT tools, such as Informatica Power Center, IBM Data Stage, Pentaho DI, Oracle Data Integration, etc. They have thorough understanding of SQL. They can work with all relational types of databases (MS SQL, Oracle, PosgreSQL, MySQL, etc.). Many data warehouses and ETL processes have been (and will be) created based on these tools.
For projects with high volumes of data, expectations of increased volume, and low data structure, you should look for a hard data engineer. Most likely you have heard about concepts like Big Data, Data Lakes, Amazon Web Services, Microsoft Azure, Python, Apache Airflow, Scala, Java, NoSQL databases, Hadoop, Spark, Kafka, etc. — these are all terms in the hard data engineer lexicon. This area of data work is developing at a tremendous pace. Due to the huge variety of approaches and technologies, it is more difficult to find capable hard data engineers for specific projects.
Conclusion
In general, if your BI tool can handle the ETL/ELT load, let it. Don’t complicate the infrastructure with extra tools. If the BI tool doesn’t work well, first make sure that you’re using this tool in accordance with best practices. (We mentioned in a previous article that, very often, customers blame a BI tool for what is in fact the fault of poor development.)
If you’re confident that you need additional tools for working with data, this article should help you understand where to start looking. As usual, by answering the questions of today, we encounter new ones tomorrow.
- How will additional ETL/ELT processes affect us?
- How will separate ETL/ELT tools interact with the data source and the BI tool? and so on…
We will cover these questions in a future article, exploring what a single point of truth is, how to store data, who is responsible for storing data, and what data we can prepare for the BI tool using ETL/ELT.
YOU MAY ALSO BE INTERESTED IN
- Data Migration to Cloud: What You Will Get in the End
- Why Migrating to the Cloud Brings Value
- Data Literacy: The ABCs of Business Intelligence
- BI Tools Comparison: How to Decide Which Business Intelligence Tool is Right for You
- Unsuccessful examples of BI development. Part I
- Examples of Unsuccessful BI Development. Part II
- BI Implementation Plan
- IBA Group Tableau Special Courses
- Integrating Power BI into E-Commerce: How to Succeed in Rapidly Developing Markets
- Analytics vs. Reporting — Is There a Difference?
- Better Business Intelligence: Bringing Data-Driven Insights to Everyone with IBM Cognos Analytics 11