Databricks vs Snowflake: Is There Really a Winner?
Table of contents
A tool for business analysts, an app for data engineers, a platform for streaming data in real-time, a place to store historical information… You are not alone in feeling confused by this chaotic tech stack, and it could well be a fundamental element in turning your organization into a data-driven business. You’d likely be glad if someone constructed a one-size-fits-all solution out of this complex mix of technologies to transform data into valuable insights, products, and services.
Databricks and Snowflake are currently the major players seeking to deliver unified cloud-native data platforms for various use cases. Although they started out in different areas of data management, their evolution led to their increasing penetration in each other’s markets, triggering a Databricks vs Snowflake battle. While the platforms are moving to the modern Lakehouse concept (although at a different pace), they maintain some advantages and disadvantages specific to their origins. We sliced and diced all the main aspects of these solutions to give you a better understanding of their preferred usage. So, what is the difference between Databricks and Snowflake?

Databricks vs Snowflake: Data Warehousing and Architecture
Data Architecture
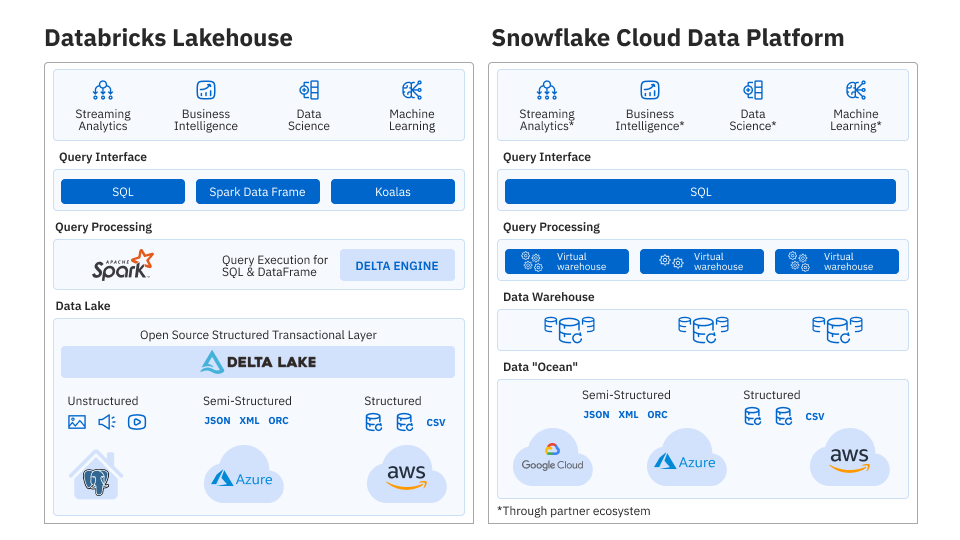
The primary difference between Databricks and Snowflake is the architecture at the root of their data warehousing solutions. The first platform positions itself as a Lakehouse, which adds a transactional storage layer, an open-source Delta Lake framework, to data lakes built in AWS, Azure, and Google clouds. As such, Databricks can handle large volumes of raw data and supports both batch and stream processing, making them a perfect fit for real-time analytics, machine learning, data engineering, and data science.
Unlike Databricks, Snowflake is a modern take on SQL data warehousing designed to work with structured information. The platform extends the classic warehouse capabilities by using multiple compute nodes combined into clusters called virtual warehouses. It also supports Apache Iceberg, an open-source table format, to bridge the gap between the warehouse and lake architectures and deliver the possibility of data lake management directly from Snowflake. However, the platform is still better suited to database management, batch processing, and serving industry-specific BI solutions.
Data Structures
Both Databricks and Snowflake can cope with semi-structured and structured data, but the latter has limited support for unstructured workloads. These elements can include text, images, audio, and video. Since the platform can work with all data types, it paves the way for greater data usability, particularly as today’s businesses collect tons of information in various formats.
Table-level Partition and Pruning Techniques
When comparing Databricks vs Snowflake in terms of query performance optimization, both platforms can divide and group data in their tables for easier management and querying. Snowflake automatically divides it into micro-partitions, which are the platform’s unique storage units and partitioning forms. It arranges groups of rows into columns and collects clustering metadata for each micro-partition to describe distribution across the units. Snowflake prunes micro-partitions that don’t contain data matching a filter specified in a query and then prunes by column within the remaining micro-partitions
Databricks also supports table-level partitioning and lets users split datasets based on certain keys for further pruning. However, the platform doesn’t advise partitioning tables that contain less than 1TB of data, recommending the use of Z-ordering instead. This technique groups related data, such as “category” and “price,” in the same set of files for faster reading. Databricks’ users can combine partitioning (for low cardinality fields) and Z-ordering (for queries spanning multiple dimensions).
Platform Focus
Another difference between Databricks vs Snowflake is seen in the platforms’ approach to building their ecosystems. While Snowflake is more dependent on third-party services, for example, external dashboards or BI tools, it tries to compensate for this by enabling users to run any type of data application directly on the platform with the combination of Snowpark Container Services and the Snowflake app marketplace. In its turn, Databricks focuses on delivering out-of-the-box solutions, releasing users of the need to search for and buy separate tools. For example, they try to streamline data lake management by forcing out third-party data catalog offerings with their own Unity Catalog.
Scalability
Databricks and Snowflake are similar in terms of their high performance and great scalability due to storage and compute separation. Snowflake combines shared-disk and shared-nothing architectures for better performance and simpler data management while letting the data processing and storage layers scale independently. The platform offers virtual warehouses of different sizes, which can be reconfigured on the fly and set to automatically resume or suspend based on workloads, along with multi-cluster warehouses for both static and dynamic resource allocation.
Databricks also splits storage and computing by using Amazon S3 for centralized cloud data storage and connecting Apache Spark clusters for data processing. However, Databricks’ architectures can vary depending on customer configurations, which makes things a bit more complicated. The platform offers a choice of computing resources for different use cases and enables flexible scaling options, including autoscaling, but this diversity often adds challenges to cluster creation and management when comparing Databricks versus Snowflake.
Migration to the Platform
Where Snowflake wins the Databricks vs Snowflake competition is in terms of the ease of migration. Since its design is based on the data warehouse architecture, Snowflake is closer to traditional data warehousing solutions that rely on relational tables. As a data lakehouse, Databricks requires more configuration and a deeper understanding of how to set clusters and other features to specific workloads.
Databricks vs Snowflake: Data Engineering and Integration
Data Engineering
When it comes to the features required for streamlined data engineering, Databricks has the winning hand in the Databricks vs Snowflake battle. Data engineers can benefit from the flexibility and vast customization opportunities of Apache Spark, alongside collaborative Databricks notebooks, powerful data pipelining capabilities for ETL workloads provided by Delta Live Tables, and other robust tools. Although Snowflake also offers tools for building data pipelines, it excels as a well-managed warehouse rather than a data engineering platform
Data Integration
Although Snowflake’s customers usually use external data integration tools while users of Databricks interact with data directly in cloud storage, this point of the Databricks and Snowflake comparison looks pretty much like a draw. Both platforms boast a wide selection of methods to ingest data from various sources. Snowflake uses the COPY INTO command, adds the possibility of running SQL commands on a defined schedule using a serverless compute model, and offers a fully managed data ingestion service, Snowpipe, for automated data loads. It also provides connectors to external systems, such as Kafka Connector, for real-time loading, and it supports popular data integration tools like Fivetran, Stitch, and Airbyte.
Databricks also allows users to choose between Autoloader and COPY INTO. It uses Apache Spark Structured Streaming to power streaming ingestion and incremental batch ingestion, offers native connectors for enterprise applications and databases, and enables low-code data loading with the help of third-party tools, including Fivetran and Hevo, through Partner Connect. Moreover, Databricks features managed volumes and Unity Catalog objects similar to Snowflake tables. Snowflake mimics the Databricks data interaction model by eliminating ingestion for Apache Iceberg tables.
Data Transformation
It doesn’t make a big difference whether you decide to use Databricks or Snowflake tools for data transformation. Both platforms support third-party solutions like dbt, Airflow, Dagster, and Prefect and can run SQL workloads in virtual warehouses, although Databricks also offers a traditional SQL warehouse option in its Classic Compute Plane. Snowflake customers typically combine Tasks, Stored Procedures, Dynamic Tables, and Materialized Views, while in Databricks, users create Jobs and Tasks in Workflows and transform data with Delta Live Tables.
Data Processing
Usually, users prefer Databricks to Snowflake for data processing in real-time since the Lakehouse solution uses powerful Spark Streaming and Structured Streaming. Snowflake’s support for stream processing is limited, and the platform is better suited for batch processing.
Query Performance
In one of the above paragraphs of this Databricks to Snowflake comparison, we already mentioned Snowflake’s virtual warehouses, which are independent compute clusters with a fixed amount of CPU, memory, and temporary storage. Each of them has its own set of nodes performing SQL and DML operations in parallel, which results in high query performance. Snowflake’s columnar storage, caching, clustering, and optimization features also add to its performance, but this doesn’t mean the platform wins the Databricks vs. Snowflake challenge.
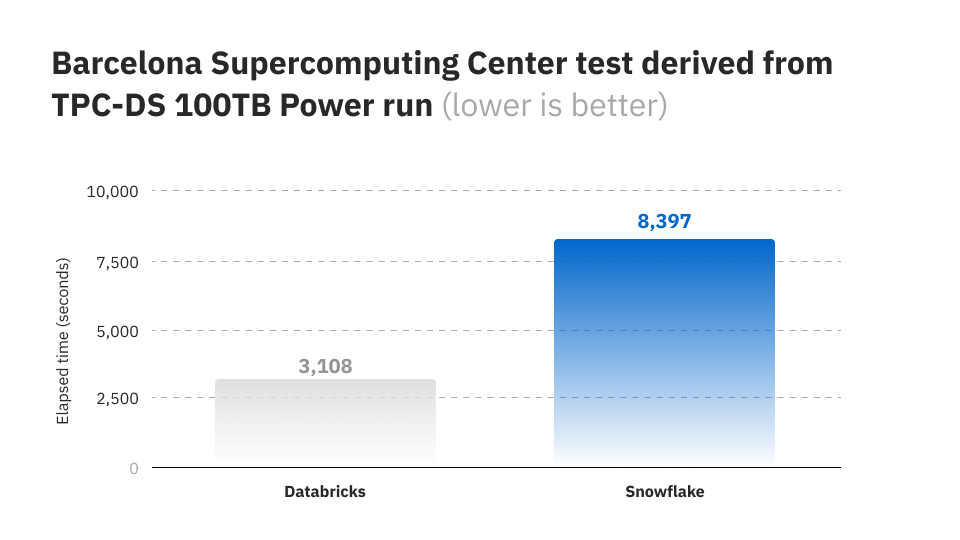
Although warehouses are traditionally considered faster in querying than Lakes and Lakehouses, Databricks managed to change the game by introducing Delta Engine, which combines a query optimizer, a caching layer, and Photon, a C++ execution engine capable of massively parallel processing. This allowed the platform to improve the performance of both large and small queries and even claim to set a warehousing performance record, thus outperforming Snowflake. Users can also customize the data platform performance with advanced indexing, hash bucketing, and other optimization features.
To resolve the Databricks vs Snowflake performance issue, it’s safe to say that Snowflake still performs better at interactive queries as it optimizes storage at the time of ingestion, while its rival excels in handling extremely challenging workloads and is competitive in BI use cases.
Data Sharing
Both platforms offer marketplaces where their customers can securely share datasets, AI models, and other data assets without tiresome ETL and costly replication. Approaching the Databricks vs Snowflake competition from the maturity point of view, the second platform, which was launched in 2019, looks more attractive, as there is a three-year lag in the Databricks marketplace implementation. However, Snowflake sticks to proprietary sharing, limiting the marketplace usage to its customers, while Databricks supports cross-platform sharing through its open-source Delta Sharing protocol.
Data Governance and Management
Databricks allows the use of its Unity Catalog to centralize access control, track data lineage, discover and manage data and AI assets, and configure identity and audit logging. It provides system tables to monitor account usage and explore billable usage records, SKU pricing logs, compute metrics, and other operational data. However, the tables only display Databrick’s costs and provide no visibility into cloud expenses, which makes Databricks yield the palm in the Databricks vs Snowflake battle to Snowflake’s cost management suite. It comes with helpful features for controlling expenditure, such as budgets and resource monitors, on top of diverse object metadata and historical usage records. Besides, Snowflake consolidated its data governance capabilities in Snowflake Horizon, a built-in solution for data security and compliance.
Deployment and Management
Databricks allows the use of its Unity Catalog to centralize access control, track data lineage, discover and manage data and AI assets, and configure identity and audit logging. It provides system tables to monitor account usage and explore billable usage records, SKU pricing logs, compute metrics, and other operational data. However, the tables only display Databrick’s costs and provide no visibility into cloud expenses, which makes Databricks yield the palm in the Databricks vs Snowflake battle to Snowflake’s cost management suite. It comes with helpful features for controlling expenditure, such as budgets and resource monitors, on top of diverse object metadata and historical usage records. Besides, Snowflake consolidated its data governance capabilities in Snowflake Horizon, a built-in solution for data security and compliance.
Databricks vs Snowflake Analytics and ML/AI Integration
Analysis and Reporting
Databricks and Snowflake are quite similar in terms of their selection of third-party tools for BI and analytics, listing integrations with major platforms like Tableau, Looker, and PowerBI. Besides, Snowflake allows users to create dashboards and visualize query results with charts in Snowsight, its web interface. It also provides access to LLM-powered Copilot, which simplifies data analysis, and an open-source Python library, Streamlit, which serves for building custom BI apps.
Databricks, in turn, supports exploratory data analysis with advanced visualizations in both Databricks SQL and notebooks. Moreover, the platform enables self-service data analysis with the Databricks AI/BI product, which includes a low-code, AI-assisted dashboarding solution alongside Genie, a conversational interface with adaptable visualizations and suggestions.
ML/AI
This part of the Databricks vs Snowflake competition is clearly not to the latter’s advantage. Databricks is designed as a one-stop platform for building end-to-end AI/ML pipelines. It features integration with cloud data storage, comprehensive data lake management, built-in ML libraries, such as MLlib and Tensorflow, and all the tools required to train, manage, deploy, and monitor models. Databricks stands out for its strong Python support, MLflow, a powerful open-source MLOps platform, and AutoML, a low-code automation tool.
Unlike Databricks, Snowflake has its AI/ML capabilities scattered across different products and features rather than creating a dedicated ecosystem. It offers a suite of large language models in Cortex, provides ready-to-use ML Functions for ML workflows in SQL, gives access to APIs in the Snowpark library for building custom ML workflows in Python, and allows users to deploy their ML models directly in Snowflake via the recently released Snowpark Container Services.
Collaboration and Notebooks
Although both Databricks and Snowflake now offer a collaborative notebook experience (Snowflake added this opportunity in 2024), Databricks’ interactive programming solution is more feature-rich and supports not only Python and SQL but also Scala and R. In addition, the platform ensures easier development and smoother collaboration by linking Databricks clusters to popular IDEs, such as Visual Studio Code, PyCharm, and IntelliJ IDEA, using Databricks Connect. Snowflake cannot boast such collaboration capabilities, but it provides numerous integrations with third-party tools instead
Databricks vs Snowflake: Security and Compliance
There is no difference between Databricks and Snowflake in terms of their approach to data security and compliance, despite the fact that with Databricks, data resides on a network managed by the client, while Snowflake manages data in its own network. Both platforms support data encryption at rest and in transit, role-based access control, multi-factor authentication, network isolation, auditing, and compliance certifications, including HIPAA, GDPR, and FedRAMP. Among other security features, Snowflake offers Dynamic Data Masking for sensitive data protection, and Databricks provides a data lake firewall, integration with Azure Active Directory for authentication and authorization, and an automated Security Analysis Tool.
Databricks vs Snowflake: Costs and User Experience
Costs
Databricks and Snowflake are cost-effective data solutions since they allow for scaling up and down as workloads change. However, on Databricks, users only pay for the resources they use, while with Snowflake, customers need to choose from pre-configured compute resources, which can lead to their underutilization and, in turn, wasted funds.
On the other hand, Databricks has a slightly more complicated pricing structure, which includes the costs of cloud data storage, Databricks service, and cloud computing, whereas Snowflake’s pricing consists of data storage and computing. Additionally, we need to factor in expenditures on the workforce required to build and maintain workflows and apps on the platforms. The human costs can be higher for Databricks, as it is trickier to configure and manage. All in all, Snowflake tends to be cheaper at high compute volumes, while Databricks comes with more consistent, predictable costs and is more flexible in suiting the needs of organizations of various sizes.
Expertise
As it supports Java, Scala, and Python, Snowflake is the number one destination for data analysts and SQL-focused developers. Databricks serves a wider audience, including analysts, data scientists, and data engineers, but is more technically demanding, requiring strong skills in Python, Scala, and R.
Service Model
A significant difference between Databricks and Snowflake also lies in their service models, as the first one offers a PaaS solution (platform as a service), while the second is a SaaS platform (software as a service). The PaaS model wins in terms of flexibility and providing customers with better control over their data, but SaaS is easier to use.
Vendors
Databricks and Snowflake easily integrate with major cloud platforms — AWS, Azure, and GCP. However, some of Databricks’ tools, such as Delta Sharing and MLflow, fail to work seamlessly across all the clouds. At the same time, Snowflake’s multi-cloud promise is compromised by vendor lock-in.
UI
For querying and managing data, Snowflake provides a web-based graphical UI called Snowsight, which is clean and easy to navigate. Databricks also offers a graphical interface for interacting with workspace folders and has a web-based notebook interface for data exploration, visualization, and analytics, which comes with a steeper learning curve since it is designed for technical users.
Reviews
The Databricks vs. Snowflake review analysis shows that users appreciate both platforms, with 74% of them giving them more than four points out of five. However, Databricks seems to outperform its competitor, having a slightly higher number of positive reviews.
Market Share
There is no proven information on Databricks and Snowflake’s market share in data platforms, but some sources estimate Snowflake’s market share in data warehousing solutions as almost 22% while giving Databricks nearly 16% of the big data analytics market.
Isolated Tenancy
Both Databricks and Snowflake provide their customers with several options for getting dedicated resources. Snowflake supports multi-tenant pooled resources and makes isolated tenancy available via the Virtual Private Snowflake (VPS) tier. Databricks’ customers can use the control plane in their accounts, data plane and storage in VPC, and a serverless SQL that runs in a multi-tenant environment.
Databricks vs Snowflake: Bottom Line
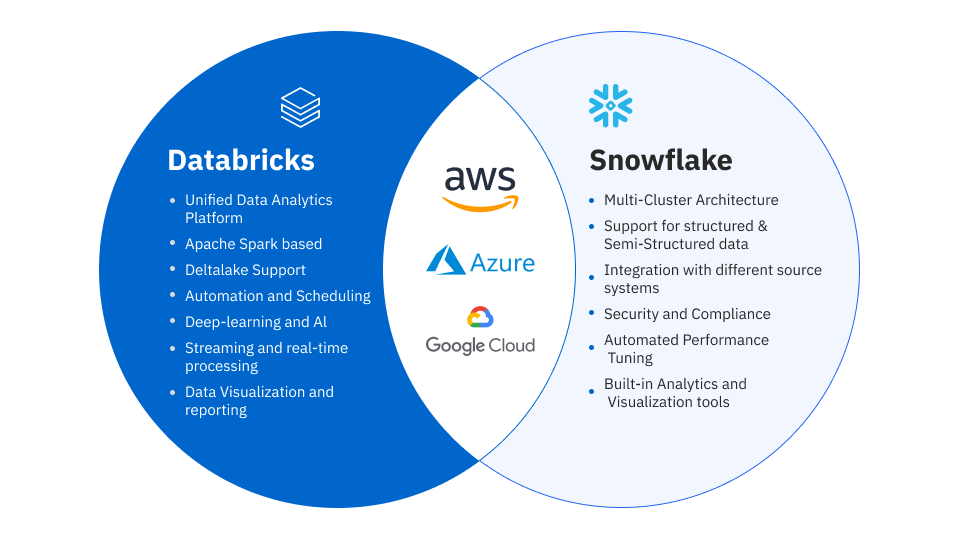
Despite the initial differences in their focus areas, Databricks and Snowflake have been turning into closer rivals as the first platform gains query performance and the second adds ML features to its ecosystem. Still, Snowflake remains mainly a data processing and data warehousing solution, and Databricks thrives as a data and AI platform. However, nowadays, it is not uncommon to see Databricks and Snowflake integrations, where Databricks is used as a data lake management solution for unstructured data and an ETL pipeline for further data processing, resulting in organized data to store and manipulate in Snowflake.
Certainly, learning how Databricks is different from Snowflake will not be enough to construct a complex integration or choose the best suite of features to solve a specific problem. You are invited to get a free consultation from experienced data engineers from the IBA Group, who have deep expertise in building various types of custom data warehousing solutions. Specify the details of your problem in the form, and we will come up with ideas on how to solve it with a cost-effective data solution.
YOU MAY ALSO BE INTERESTED IN
- On the Way to Lakehouse
- Cloud vs On-premises: What is Better for Business?
- Why Migrating to the Cloud Brings Value
- Data Migration to Cloud: What You Will Get in the End
- Why Migrating to the Cloud Brings Value
- ETL/ELT: What They Are, Why They Matter, and When to Use Standalone ETL/ELT Tools
- Data Literacy: The ABCs of Business Intelligence
- BI Tools Comparison: How to Decide Which Business Intelligence Tool is Right for You
- Unsuccessful examples of BI development. Part I
- Examples of Unsuccessful BI Development. Part II
- BI Implementation Plan
- IBA Group Tableau Special Courses
- Integrating Power BI into E-Commerce: How to Succeed in Rapidly Developing Markets
- Analytics vs. Reporting — Is There a Difference?
- Better Business Intelligence: Bringing Data-Driven Insights to Everyone with IBM Cognos Analytics 11